Getting Started....
Microsoft Power BI is
reach of features, rich graphics and supports numerous data sources.
To use MS Power BI
features you have to signup here. https://powerbi.microsoft.com/
- User your organization Email Id for signing up.
Microsoft will use your Organization Office 365 Licensing for this.
- It verifies your organization email id and
Password.
- You will get free access but will be limited to few sources and samples only.
- To have full access you need to purchase Power BI Pro features.MS provide a 60 days trial pack for pro features :-)
- Once sign up it will take few seconds to setup
a Power BI work environment for you.
- Following which it will allow you to connect
to you with multiple data source options within or outside your
organizations

- Here I am creating a sample data source using
Xlsx (Local File Source) as Source
- you will get following like environment

- It same as Excel Pivot with little bit
different layout but more charts like MAPs.
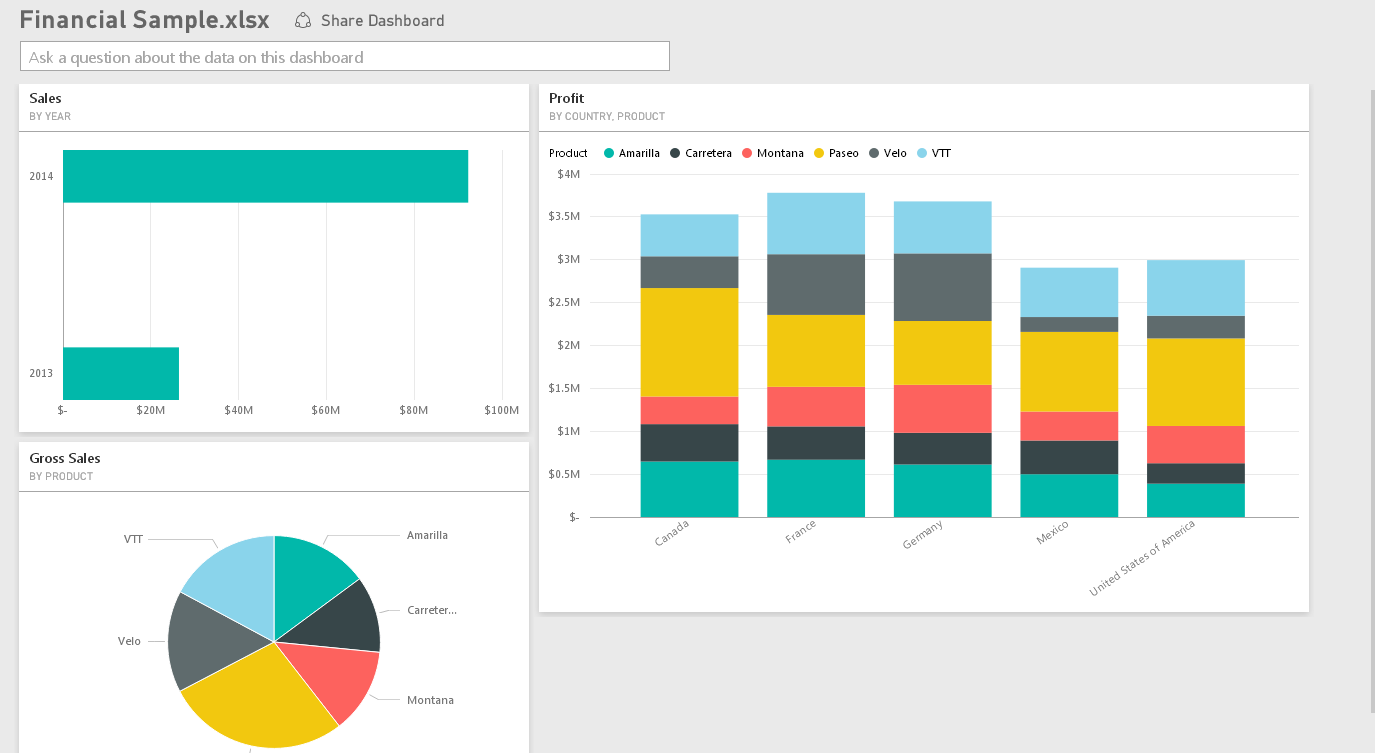
- Following is a sample report-

- Overall dashboards will look like
Well I have just started
here. Please look for more on this in coming days…………………..





